
Tesseract OCR integration
Tesseract was originally developed at Hewlett-Packard Laboratories Bristol and at Hewlett-Packard Co, Greeley Colorado between 1985 and 1994, with some more changes made in 1996 to port to Windows, and some C++izing in 1998. In 2005 Tesseract was open sourced by HP. Since 2006 it is developed by Google. Tesseract has unicode (UTF-8) support, and can recognize more than 100 languages "out of the box".
Using Tesseract OCR and looking for integration service?
Easy connect Tesseract OCR with other services, setup notifications about events or enable communication in chats, automate data sync, data analytics and BI
Connect Tesseract OCR with other services in few minutes
Easy integrate Tesseract OCR and connect realtime online data sync with other services: WhatsApp, Slack, Power BI, Google Looker Studio and many more

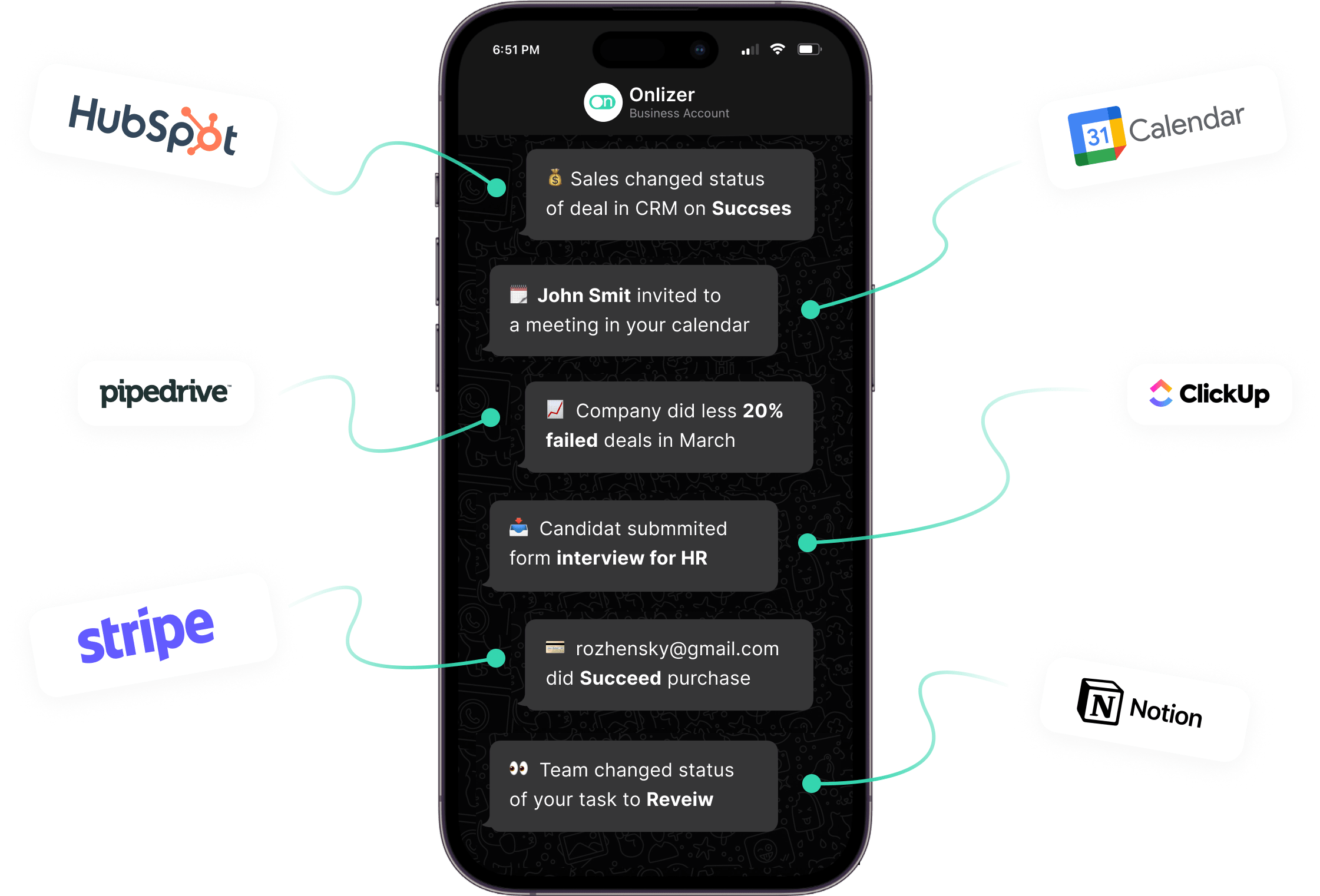
Notify for Tesseract OCR
Track important events in Tesseract OCR and send them to WhatsApp, Telegram, Discord and other messengers
Setup send and receive notifications for events in Tesseract OCR in a few minutes
Chats
Talk to your customers from Tesseract OCR and close deals faster via omni-channel communication
Onlizer Chats connects Tesseract OCR to WhatsApp, Telegram, Viber and other messengers to send and receive messages, sync chats, add contacts and deals on the fly, schedule tasks and track activities.
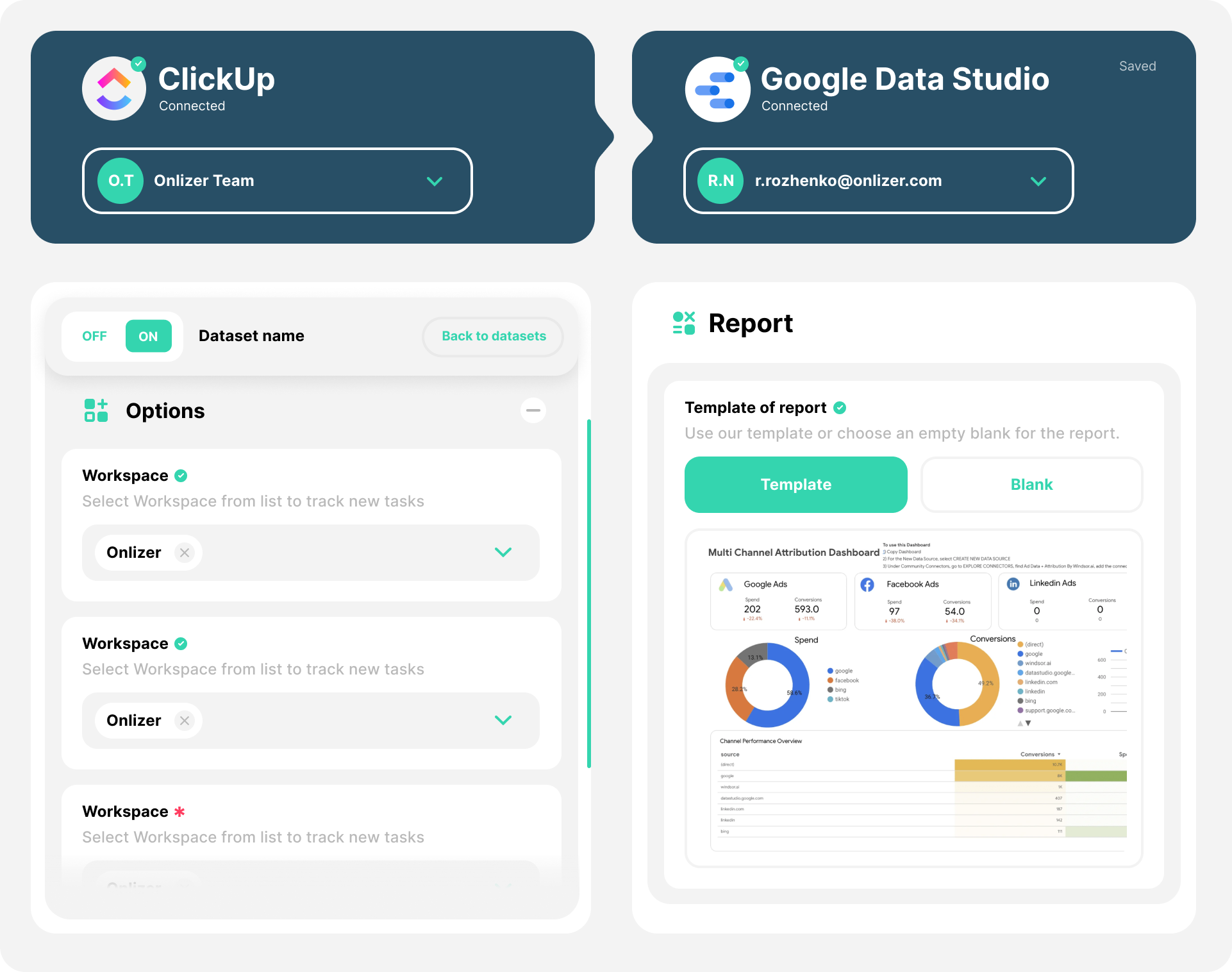
Onlizer BI
Connect Tesseract OCR as data source and import data and insights with integration to Power BI, Google Looker Studio, Google Data Studio and other BI services
Onlizer BI integrates data from your Tesseract OCR to Power BI, Google Looker Studio (former Google Data Studio), Tableau and other BI tools to analyze contacts, deals, tasks and other data on the fly, build dashboards and get insights quickly.
Tesseract OCR integration ideas
Support or submit Tesseract OCR integration idea and we'll invite you to use it early for free! Our development team will reach you personally with estimation for this request. Also you can vote for most relevant suggestions below.
Build Tesseract OCR integration with no-code tools
You can easy create integration for Tesseract OCR using no-code builder and customize it to fit your needs. Onlizer provides wide range of services to connect with Tesseract OCR
Do not see required feature or service in least? Send us integration request. We carefully listen to our community and implement new integrations on demand.
Check most popular integrations for Tesseract OCR
- Tesseract OCR + WhatsApp integration
- Tesseract OCR + Slack integration
- Tesseract OCR + Power BI integration
- Tesseract OCR + Google Looker Studio integration
- Tesseract OCR + WooCommerce integration
- Tesseract OCR + Zendesk integration
- Tesseract OCR + Notion integration
- Tesseract OCR + ClickUp integration
- Tesseract OCR + Google Calendar integration
- Tesseract OCR + Zoho CRM integration
All Tesseract OCR integrations
- Tesseract OCR + 2Checkout integration
- Tesseract OCR + ActiveCampaign integration
- Tesseract OCR + Adobe Analytics integration
- Tesseract OCR + Airtable integration
- Tesseract OCR + Amazon integration
- Tesseract OCR + Amazon DynamoDb integration
- Tesseract OCR + Amazon Redshift integration
- Tesseract OCR + Amazon S3 integration
- Tesseract OCR + Amazon SES integration
- Tesseract OCR + Apache HBase integration
- Tesseract OCR + Apache Hive integration
- Tesseract OCR + Apple Calendar integration
- Tesseract OCR + Apple Reminders integration
- Tesseract OCR + Appointedd integration
- Tesseract OCR + Asana integration
- Tesseract OCR + Azure Blob Storage integration
- Tesseract OCR + Azure DevOps integration
- Tesseract OCR + Azure DocumentDb integration
- Tesseract OCR + Azure Notifications Hubs integration
- Tesseract OCR + Azure Table Storage integration
- Tesseract OCR + Basecamp 3 integration
- Tesseract OCR + Baserow integration
- Tesseract OCR + BigCommerce integration
- Tesseract OCR + Bing Maps integration
- Tesseract OCR + Bing Translation integration
- Tesseract OCR + Bitbucket integration
- Tesseract OCR + Bitly (bit.ly) integration
- Tesseract OCR + Box integration
- Tesseract OCR + Brevo integration
- Tesseract OCR + Bridgecrew integration
- Tesseract OCR + Bubble integration
- Tesseract OCR + Buffer integration
- Tesseract OCR + Calendly integration
- Tesseract OCR + CallRail integration
- Tesseract OCR + Canny integration
- Tesseract OCR + Canva integration
- Tesseract OCR + ChatGPT integration
- Tesseract OCR + Chatra integration
- Tesseract OCR + Clearbit integration
- Tesseract OCR + Clerk integration
- Tesseract OCR + Clickatell integration
- Tesseract OCR + ClickFunnels integration
- Tesseract OCR + Coda integration
- Tesseract OCR + Coinbase Commerce integration
- Tesseract OCR + Confluence integration
- Tesseract OCR + ConnectWise Manage integration
- Tesseract OCR + Contact Form 7 integration
- Tesseract OCR + Crowdin integration
- Tesseract OCR + Crypto Utilities integration
- Tesseract OCR + CSV integration
- Tesseract OCR + Customer.io integration
- Tesseract OCR + Data Storage integration
- Tesseract OCR + Databox integration
- Tesseract OCR + Date and time operations integration
- Tesseract OCR + Deel integration
- Tesseract OCR + Delay integration
- Tesseract OCR + Demio integration
- Tesseract OCR + Discord integration
- Tesseract OCR + DocDream integration
- Tesseract OCR + DocuSign integration
- Tesseract OCR + Drift integration
- Tesseract OCR + Dropbox integration
- Tesseract OCR + Drupal integration
- Tesseract OCR + Dubsado integration
- Tesseract OCR + eBay integration
- Tesseract OCR + Elasticsearch integration
- Tesseract OCR + Email integration
- Tesseract OCR + eSputnik integration
- Tesseract OCR + Etsy integration
- Tesseract OCR + EVE.calls integration
- Tesseract OCR + Evernote integration
- Tesseract OCR + EverWebinar integration
- Tesseract OCR + Expandi integration
- Tesseract OCR + Exponea integration
- Tesseract OCR + ezeepBlue integration
- Tesseract OCR + Facebook Conversions integration
- Tesseract OCR + Facebook Marketing API integration
- Tesseract OCR + FastSpring integration
- Tesseract OCR + Firmao integration
- Tesseract OCR + FlutterFlow integration
- Tesseract OCR + Fondy integration
- Tesseract OCR + Foursquare integration
- Tesseract OCR + FreshBooks integration
- Tesseract OCR + Freshdesk integration
- Tesseract OCR + Frill integration
- Tesseract OCR + FTP integration
- Tesseract OCR + GetResponse integration
- Tesseract OCR + Ghost integration
- Tesseract OCR + Git integration
- Tesseract OCR + GitHub integration
- Tesseract OCR + GitLab integration
- Tesseract OCR + GMail (Google Mail) integration
- Tesseract OCR + GoodData integration
- Tesseract OCR + Google Analytics integration
- Tesseract OCR + Google Cloud Vision API integration
- Tesseract OCR + Google Contacts integration
- Tesseract OCR + Google Data Studio integration
- Tesseract OCR + Google Docs integration
- Tesseract OCR + Google Drive integration
- Tesseract OCR + Google Forms integration
- Tesseract OCR + Google Maps integration
- Tesseract OCR + Google People API integration
- Tesseract OCR + Google Sheets integration
- Tesseract OCR + Google Tasks integration
- Tesseract OCR + Google Translation integration
- Tesseract OCR + GoToWebinar integration
- Tesseract OCR + Gravity Forms integration
- Tesseract OCR + Gupshup WhatsApp integration
- Tesseract OCR + Harvest integration
- Tesseract OCR + Hellonext integration
- Tesseract OCR + Heroku integration
- Tesseract OCR + HTML Parser integration
- Tesseract OCR + HTTP integration
- Tesseract OCR + Huboo integration
- Tesseract OCR + HubSpot integration
- Tesseract OCR + Images operations integration
- Tesseract OCR + Infobip integration
- Tesseract OCR + Infogram integration
- Tesseract OCR + Insightly integration
- Tesseract OCR + Instagram integration
- Tesseract OCR + Intercom integration
- Tesseract OCR + Interkassa integration
- Tesseract OCR + Iterable integration
- Tesseract OCR + Iterator integration
- Tesseract OCR + Jira integration
- Tesseract OCR + JSON integration
- Tesseract OCR + JustClick integration
- Tesseract OCR + Justin integration
- Tesseract OCR + Kaizala integration
- Tesseract OCR + Kajabi integration
- Tesseract OCR + Kartra integration
- Tesseract OCR + KeyCRM integration
- Tesseract OCR + KIndexer integration
- Tesseract OCR + Klaviyo integration
- Tesseract OCR + Klipfolio integration
- Tesseract OCR + Kustomer integration
- Tesseract OCR + Leadspedia integration
- Tesseract OCR + LEELOO.ai integration
- Tesseract OCR + Linear integration
- Tesseract OCR + LinkedIn integration
- Tesseract OCR + LiqPay integration
- Tesseract OCR + Livestorm integration
- Tesseract OCR + Lokalise integration
- Tesseract OCR + Looker integration
- Tesseract OCR + Lucene integration
- Tesseract OCR + Lulu integration
- Tesseract OCR + MailboxValidator integration
- Tesseract OCR + MailChimp integration
- Tesseract OCR + MailerLite integration
- Tesseract OCR + MailerLite Classic integration
- Tesseract OCR + MailGun integration
- Tesseract OCR + Mailhook integration
- Tesseract OCR + Mailigen integration
- Tesseract OCR + Manual trigger integration
- Tesseract OCR + ManyChat integration
- Tesseract OCR + MemberStack integration
- Tesseract OCR + Messenger integration
- Tesseract OCR + Metabase integration
- Tesseract OCR + Microsoft Access integration
- Tesseract OCR + Microsoft Bookings integration
- Tesseract OCR + Microsoft Dynamics 365 integration
- Tesseract OCR + Microsoft Excel integration
- Tesseract OCR + Microsoft Office365 integration
- Tesseract OCR + Microsoft SQL Server integration
- Tesseract OCR + Microsoft Teams integration
- Tesseract OCR + Microsoft To Do integration
- Tesseract OCR + Microsoft Word integration
- Tesseract OCR + Miro integration
- Tesseract OCR + Miva integration
- Tesseract OCR + Monday.com integration
- Tesseract OCR + MongoDB integration
- Tesseract OCR + MS Team Services Online integration
- Tesseract OCR + MySQL integration
- Tesseract OCR + Netlify integration
- Tesseract OCR + Nova Poshta integration
- Tesseract OCR + Odoo integration
- Tesseract OCR + Office 365 Outlook integration
- Tesseract OCR + OfficeRnD integration
- Tesseract OCR + Okta integration
- Tesseract OCR + ON24 integration
- Tesseract OCR + OneDrive integration
- Tesseract OCR + OneNote integration
- Tesseract OCR + Online Test Pad integration
- Tesseract OCR + Onlizer Contacts integration
- Tesseract OCR + Onlizer Forms integration
- Tesseract OCR + Onlizer Functions integration
- Tesseract OCR + OpenAI integration
- Tesseract OCR + OpenCart integration
- Tesseract OCR + Oracle DB integration
- Tesseract OCR + Paddle integration
- Tesseract OCR + Paddle Classic integration
- Tesseract OCR + Paperless integration
- Tesseract OCR + Patreon integration
- Tesseract OCR + Pavuk AI integration
- Tesseract OCR + PayPal integration
- Tesseract OCR + PayPro Global integration
- Tesseract OCR + PDF integration
- Tesseract OCR + PDFMonkey integration
- Tesseract OCR + Pipedrive integration
- Tesseract OCR + Pocket integration
- Tesseract OCR + Podium integration
- Tesseract OCR + PopMechanic integration
- Tesseract OCR + Poster POS integration
- Tesseract OCR + PostgreSQL integration
- Tesseract OCR + Printful integration
- Tesseract OCR + Printify integration
- Tesseract OCR + Printix integration
- Tesseract OCR + Prom.UA integration
- Tesseract OCR + Pushbullet integration
- Tesseract OCR + Qlik integration
- Tesseract OCR + QuickBooks integration
- Tesseract OCR + Random integration
- Tesseract OCR + Reckon integration
- Tesseract OCR + Redis integration
- Tesseract OCR + Redmine integration
- Tesseract OCR + Robokassa integration
- Tesseract OCR + Rossum integration
- Tesseract OCR + RSS integration
- Tesseract OCR + RudderStack integration
- Tesseract OCR + Salesforce CRM integration
- Tesseract OCR + Scaleo integration
- Tesseract OCR + Scheduler integration
- Tesseract OCR + Selzy integration
- Tesseract OCR + SemanticDesk integration
- Tesseract OCR + SemanticForce integration
- Tesseract OCR + SendGrid integration
- Tesseract OCR + Sendinblue integration
- Tesseract OCR + SendPulse integration
- Tesseract OCR + SendPulse WhatsApp integration
- Tesseract OCR + Sendy integration
- Tesseract OCR + Service Bus integration
- Tesseract OCR + SharePoint integration
- Tesseract OCR + Shopee integration
- Tesseract OCR + Shopify integration
- Tesseract OCR + short.io integration
- Tesseract OCR + Simplescraper integration
- Tesseract OCR + Skype integration
- Tesseract OCR + Smart Sender integration
- Tesseract OCR + Smartsheet integration
- Tesseract OCR + SMS.to integration
- Tesseract OCR + SMSC integration
- Tesseract OCR + SmsClub integration
- Tesseract OCR + SMXCOM integration
- Tesseract OCR + Snowflake integration
- Tesseract OCR + Softbook integration
- Tesseract OCR + Solr integration
- Tesseract OCR + Spark integration
- Tesseract OCR + SparkPost integration
- Tesseract OCR + Square integration
- Tesseract OCR + Squarespace integration
- Tesseract OCR + Streak integration
- Tesseract OCR + Stripe integration
- Tesseract OCR + SugarCRM integration
- Tesseract OCR + SurveyGizmo integration
- Tesseract OCR + Tableau integration
- Tesseract OCR + Tapix integration
- Tesseract OCR + TaxJar integration
- Tesseract OCR + Teachable integration
- Tesseract OCR + Telegram integration
- Tesseract OCR + Telegram Bot integration
- Tesseract OCR + Telegram Personal integration
- Tesseract OCR + TestRail integration
- Tesseract OCR + Text operations integration
- Tesseract OCR + Thinkific integration
- Tesseract OCR + TikTok integration
- Tesseract OCR + Tilda integration
- Tesseract OCR + Todoist integration
- Tesseract OCR + Transform integration
- Tesseract OCR + TravelTime integration
- Tesseract OCR + Trello integration
- Tesseract OCR + Trustpilot integration
- Tesseract OCR + TurboSMS integration
- Tesseract OCR + Twilio integration
- Tesseract OCR + Twitch integration
- Tesseract OCR + Twitter integration
- Tesseract OCR + Typeform integration
- Tesseract OCR + Unisender integration
- Tesseract OCR + Viber integration
- Tesseract OCR + Vibes integration
- Tesseract OCR + Vipps MobilePay integration
- Tesseract OCR + WATI integration
- Tesseract OCR + Wave integration
- Tesseract OCR + WayForPay integration
- Tesseract OCR + Web pages constructor integration
- Tesseract OCR + Web/HTTP Client integration
- Tesseract OCR + Web/HTTP endpoint integration
- Tesseract OCR + Webex integration
- Tesseract OCR + Webflow integration
- Tesseract OCR + Webflow V2 integration
- Tesseract OCR + Webhooks integration
- Tesseract OCR + WebinarJam integration
- Tesseract OCR + Weblium integration
- Tesseract OCR + WhatsApp Business integration
- Tesseract OCR + WhatsApp via Twilio integration
- Tesseract OCR + WhoAPI integration
- Tesseract OCR + Wix integration
- Tesseract OCR + WordPress integration
- Tesseract OCR + Workflow integration
- Tesseract OCR + WP Contact Form integration
- Tesseract OCR + Wunderlist integration
- Tesseract OCR + Xero integration
- Tesseract OCR + XML integration
- Tesseract OCR + YouGile integration
- Tesseract OCR + YouTrack integration
- Tesseract OCR + YouTube integration
- Tesseract OCR + ZEN integration
- Tesseract OCR + Zenoti integration
- Tesseract OCR + Zillow integration
- Tesseract OCR + ZOHO Bigin integration
- Tesseract OCR + ZOHO Books integration
- Tesseract OCR + Zoho Calendar integration
- Tesseract OCR + Zoho Cliq integration
- Tesseract OCR + ZOHO Desk integration
- Tesseract OCR + Zoho Docs integration
- Tesseract OCR + ZOHO Inventory integration
- Tesseract OCR + Zoho Subscriptions integration
- Tesseract OCR + Zoom integration
Explore Tesseract OCR integration features
You can easy create integration for Tesseract OCR using no-code builder and customize it to fit your needs.
Recognize text
Recognize text via Tesseract OCR for one or multiple languages from input image
Try action ActionLet's Try! Get Free Messages and Tasks to test Onlizer features
Start Your 14-Days Free Trial
We can help you to create your dream processes for better business revenue.